Recently I faced the situation where I had built the structures already existing on a D7 site into a new D8 site, and I wanted to try them out with some content. I thought to myself: “even if the creation of the structures has to be manual, there must be a way to export the content in an automated way”.
So I thought about this:
General Approach
-
Create some view on the D7 site that will expose the content in a machine-readable format (XML, CSV, JSON…)
-
Create a feed importer on the D8 site that will consume the newly created endpoint and put this data into nodes
Easy, right…? Well, not in Drupal’s world ![]()
So, we face some issues:
Problems
-
In order to have 1) we need to be able to expose the data in a machine-readable format, but Drupal 7 only offers RSS out of the box, and for most content types this is simply not enough (no possibility to configure fields or XML structure, RSS is a closed format)
-
In order to have 2) once we have 1) the feed importer should be able to process a custom XML/JSON/CSV dataset, and by default the Feeds module in D8 only allows for the following parsers:
- CSV
- Indico
- OPML
- RSS/Atom
- Sitemap XML
So in principle CSV should work, but after analyzing the content I realized CSV would cause trouble since my content contained tabs, semi-colons, quotes, line-breaks, and all sorts of characters that would be problematic for such simple and error-prone format. The rest of parsers are not useful for my custom content.
What is the solution? Here it goes!
Solution
I decided I would go for XML since it’s pretty resilient to inline some encoded HTML (JSON would also do, but I haven’t tried it yet).
So this is what we need to do:
Source D7 site
-
Install the Views data export module: https://www.drupal.org/project/views_data_export
-
Create a publicly accessible page view that exposes the data in XML format using this module’s view mode:
-
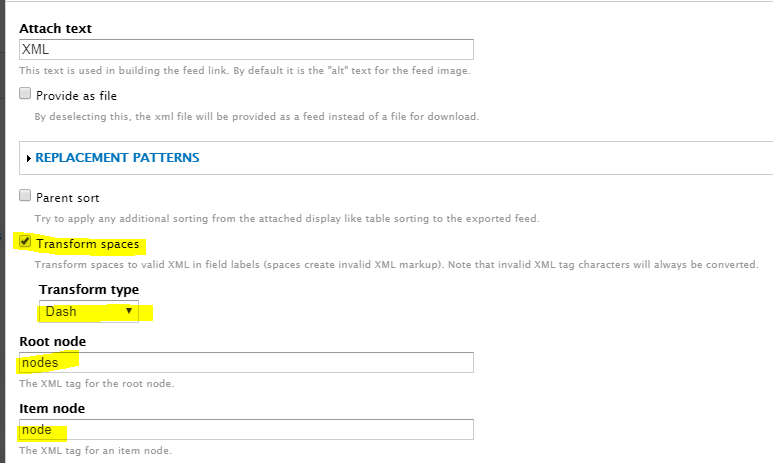
Configure the XML format in a way that’s easy to parse by the consuming feed importer. I chose some basic options but these are personal:

-
Add the fields you need to export. Keep in mind that the XML elements will get their names from the labels assigned to the fields, so I recommend using lowercase, simple names so it’s easier to configure the feed importer later
-
Set a Path on the DATA EXPORT SETTINGS section, and use None on the Access configuration, so the view is publicly accessible.
 This is important since otherwise the D8 feed importer will not be able to consume the data, because otherwise SSO will intercept the HTTP request and redirect to its login page!
This is important since otherwise the D8 feed importer will not be able to consume the data, because otherwise SSO will intercept the HTTP request and redirect to its login page! -
Once you have checked that the URL works and produces a valid XML structure, that’s publicly accessible, we can start setting up our D8 site for import!
Target Drupal 8 site
It’s assumed that the site already has a target content type with same or compatible fields configured, ready to be populated with the source nodes’ data.
This is trickier, since D8 needs some modules to make this work, and the installation is just not simple. But hopefully this guide will help. Here it goes!
Of course, if anyone wants to attempt to use Drush and Composer to get this setup quicker, please do and update this thread with your findings should you succeed!
Setting up the modules
-
The module we will need to install to provide XML/JSON/CSV parsers for the feed importer has itself some libraries dependencies, and unfortunately they cannot be installed automatically. We will need to install another module that will help installing these libraries.
The module is Ludwig: https://www.drupal.org/project/ludwig
you can do it via Drush:drush en ludwig -
Once Ludwig is installed and enabled, we need another module that will provide the parsers for the feed importer:
Feeds extensible parsers: https://www.drupal.org/project/feeds_ex
But! we need to install the dev version! Otherwise we won’t have Ludwig support and installing the libraries will be much more complicated. So we download the latest dev version (as of the date of this writing, it’s this one: https://www.drupal.org/project/feeds_ex/releases/8.x-1.x-dev)
-
Once Feeds extensible parsers has been installed and enabled, we need to use Ludwig to download the libraries and put them in the right places. This will still be manual but at least we will get some guidance so success is somehow guaranteed.
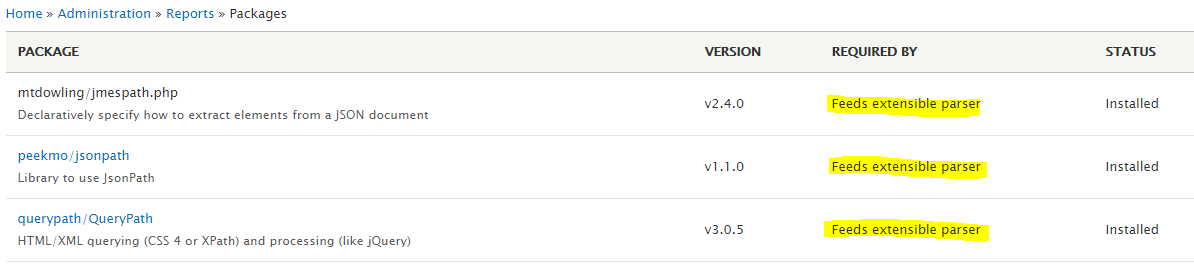
Go to
/admin/reports/packageson your site to see Ludwig’s report on libraries you might be missing. You should see something like this:In your case, because the libraries have not yet been downloaded, an option to dowload them will appear, and also information about the path were they should be put in you site’s filesystem (somewher inside
/modules/feeds_ex/lib) -
Download all the libraries, and extract the ZIP files in the paths suggested by Ludwig, verbatim. You need to mount your D8 site and access the filesystem to do this. Unfortunately Ludwig cannot do this automatically yet

-
Once done, if you refresh your Packages report page and you see the ‘Installed’ STATUS for all of them, you succeeded! Otherwise double, triple check the paths were the libraries are copied
Setting up the feed importer
Now we arrived to the important part: how to import the data coming from the D7 data export view into nodes on our D8 site. Our feeds now can parse XML and other formats, so let’s do this!
-
Create a new Feed Type. You can do this from the admin toolbar via ‘Structure > Feed types > Add feed type’ or
/admin/structure/feeds/add -
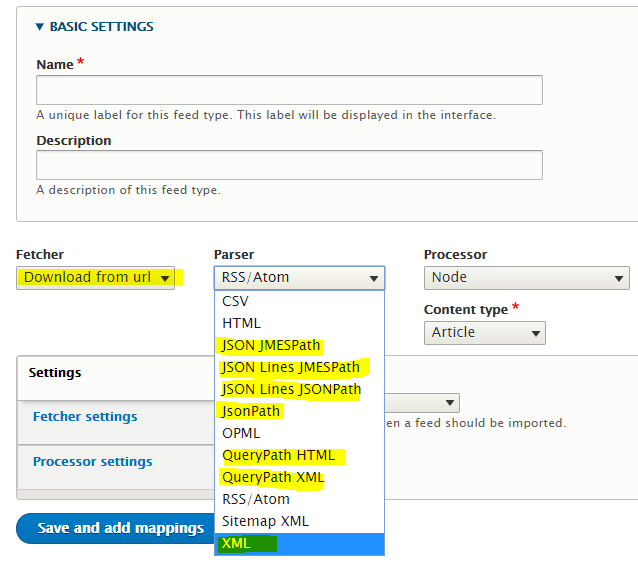
Now on the Parser dropdown select we have lots of interesting options:
For our purposes we will use the XML parser, and use ‘Download from url’ as Fetcher. We also want to use ‘Node’ as Processor and select our target Content type, which should match the exported content.
Every other configuration is as your usual feed importer, so choose wisely how often you import, what happens with existing nodes, etc.
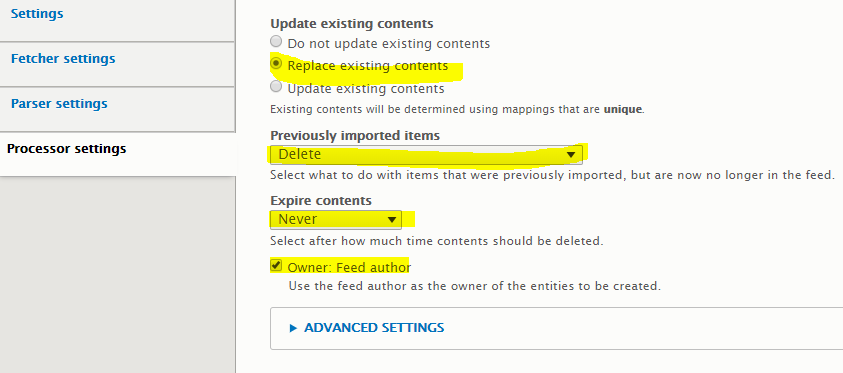
Because my main purpose was to import existing content in one go and once done forget about the feed, my configuration was to set the Import period to ‘Off’ and then the following Processor settings for the feed: -
Here’s the important part: the mapping. This is what will copy the data from the XML export into the right fields of our content type.
The way it works is by using XPath to select the right elements from the XML, so if you are not familiar with it it’s good to read a little about it: https://www.brainbell.com/tutorials/XML/XML_Data_Querying_101.htm
There’s also an online resource to test XPath expressions online: https://codebeautify.org/Xpath-TesterIf you selected
nodeas Item node as I did when you configured your Data export view (step 3 from ‘Source D7 site’), then you can use//nodeas your XPath expression for Context on your feed importer mapping:
This means that the fields XPath expressions will be evaluated for every
nodeelement on your XML dataset. This is what we want for simplicity.Now it’s just a matter of selecting every Target field on your content type, and assign each an XPath expression that will get the fields from the XML:
In this example, I am targeting the Title field on my content type, to get the information from an element called
titleinside my context which is//node, so if my XML looks like this:<?xml version="1.0" encoding="UTF-8" ?> <nodes> <node> <title>This is a title</title> <body>This is a body</body> </node> <node>...</node> ... </nodes>It will get the
<title>tag from the<node>element and populate the Title field of the newly created node.It’s that simple! Map every field and you’re up to go and attempt the first import!
Of course there are tricky parts: what about more complex data types? Well, here are some recommendations:-
Dates: use standard format:
Y-m-d H:i:s(PHP format) -
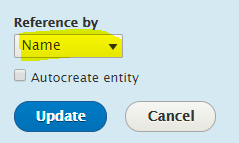
Taxonomies: select Reference by Name to avoid mismatch between the
tid’s on both sites (they will be different 99% guaranteed). Also, if you already have created the taxonomy terms, you might want to leave ‘Autocreate entity’ unchecked: -
Files:
sorry, I haven’t even tried to inline them, but I guess they can be base64-encoded and inlined in the XML. I will update this once I do testsUpdate (30.01.2020): Actually when exposing the file field as a full URL, and given that the file can be publicly accessed, the feed importer will actually download it and upload it automatically on the target site:
In this example, thephotofield is basically a URL to the image file. So I just mapped the ‘File ID’ property of the file field, chose Reference by: Filename, and rolled with it.
-
-
Finally! Import the data! Here’s the moment we’ve been waiting for! Go to ‘Content > Feeds’ and then click the ‘Add feed’ button.
If you have defined more than one feed type, you will be presented with a choice. Otherwise you will go directly to the feed configuration page.
Give your feed a name, enter the URL where the data from D7 is being exposed, cross your fingers and click on ‘Save and import’!
If it woks, you will be presented with your list of imported nodes, and you will have effectively mastered the art of synchronizing content from D7 to D8

If it didn’t work, here’s a list of Things That Might Go WrongTM (I went through them all, so don’t despair!):
-
 The data export view on the D7 site is not publicly accessible - Check that you can access the URL from a private browser without logging in. Otherwise, your D8 site can’t reach it either.
The data export view on the D7 site is not publicly accessible - Check that you can access the URL from a private browser without logging in. Otherwise, your D8 site can’t reach it either. -
The data export view on the D7 site is not generating valid XML - The data export module has its flaws and if you forget to encode your fields properly the resulting XML might not validate. You can use validators to make sure it is valid XML
-
The mapping on the D8 site’s feed is not valid - XPath can be tricky, and it can never be a bad idea to use some online XPath tester to check what you are really getting (I used this one: https://codebeautify.org/Xpath-Tester)
-
Fields are incompatible or not properly encoded - Some fields may end up blank if the source format cannot be used on the target field. This is true for dates, entity references, fields containing HTML, etc. Double-check your data export so fields are properly encoded in the simplest way possible. You might need to use ‘Field rewrite’ or calculated and custom fields to get it right.
-


Conclusion
This was difficult to accomplish and requires certain technical skills but the results are worth it if you need to export hundreds of nodes, so I hope it’s useful!
Happy hacking!